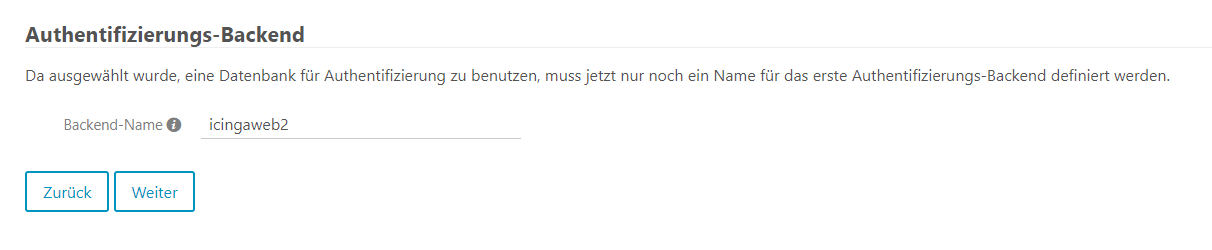
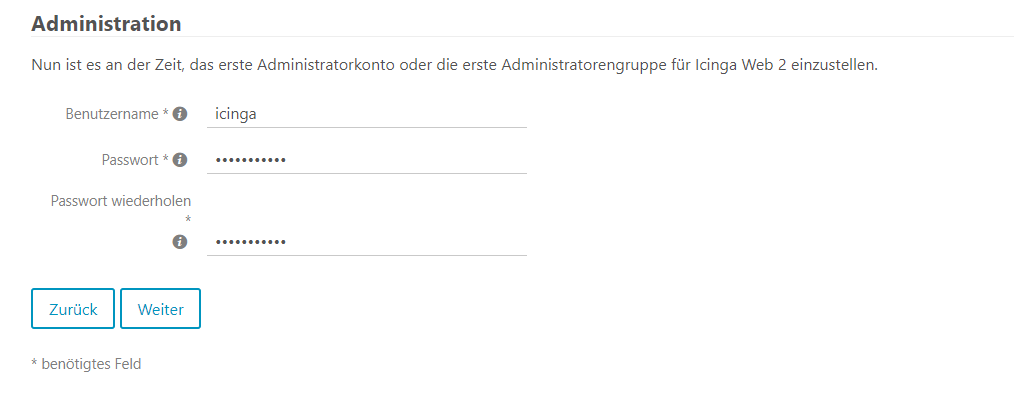
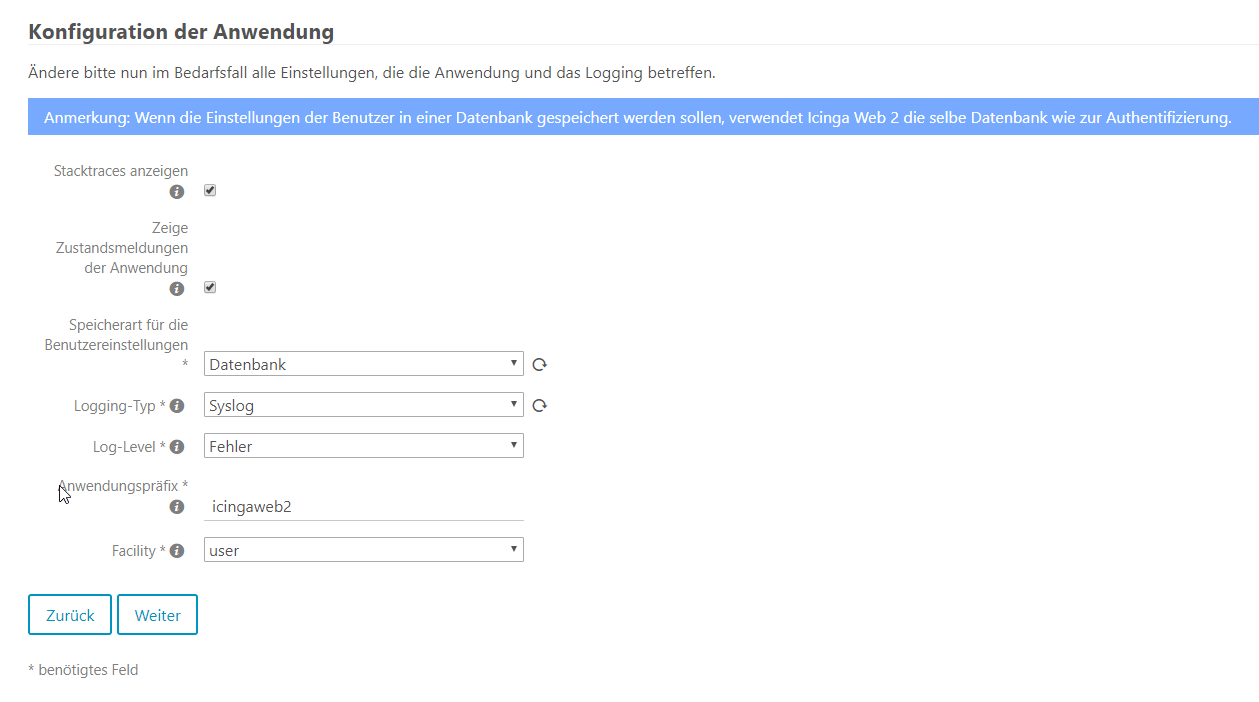
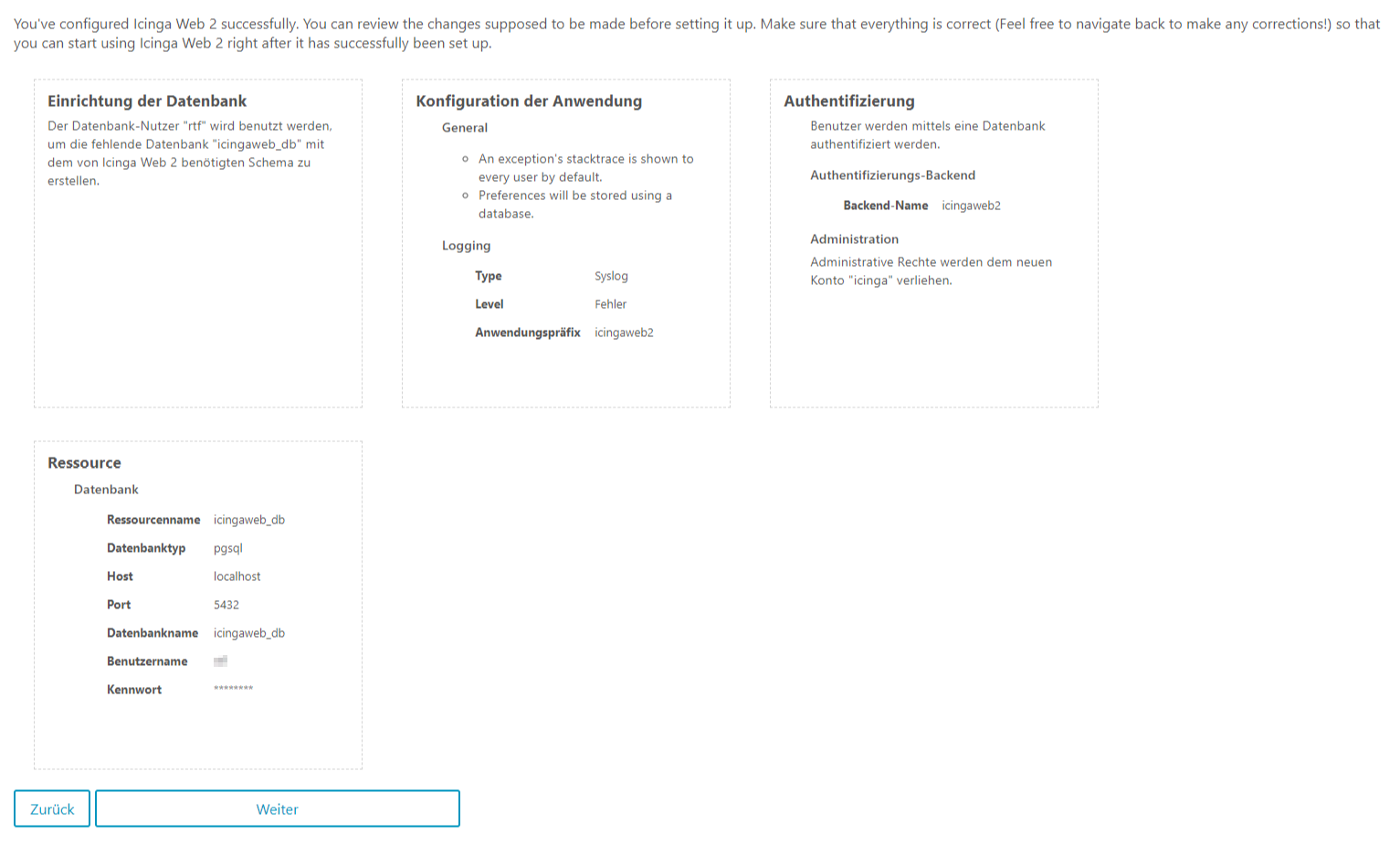
Meteor Neowise
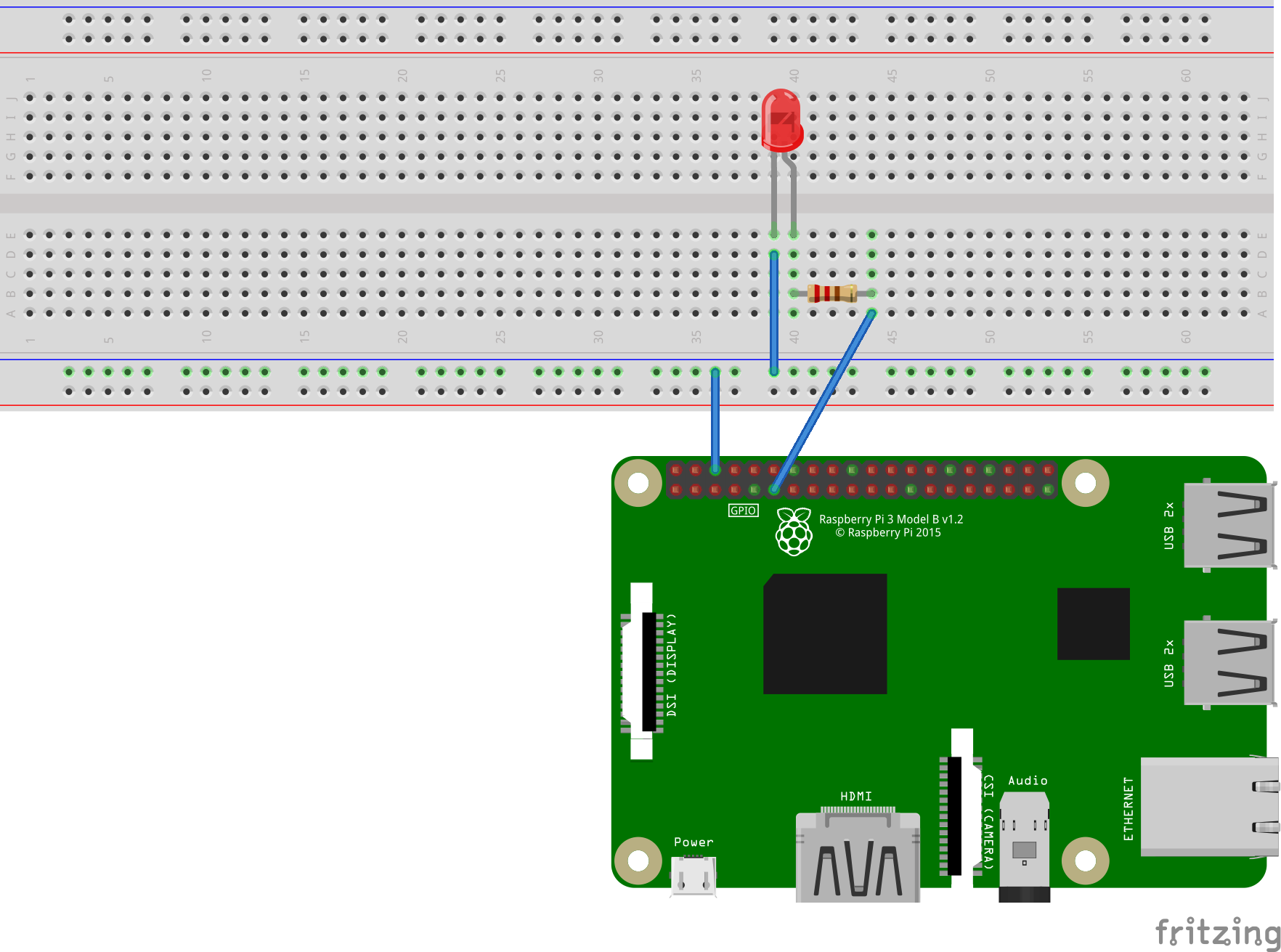
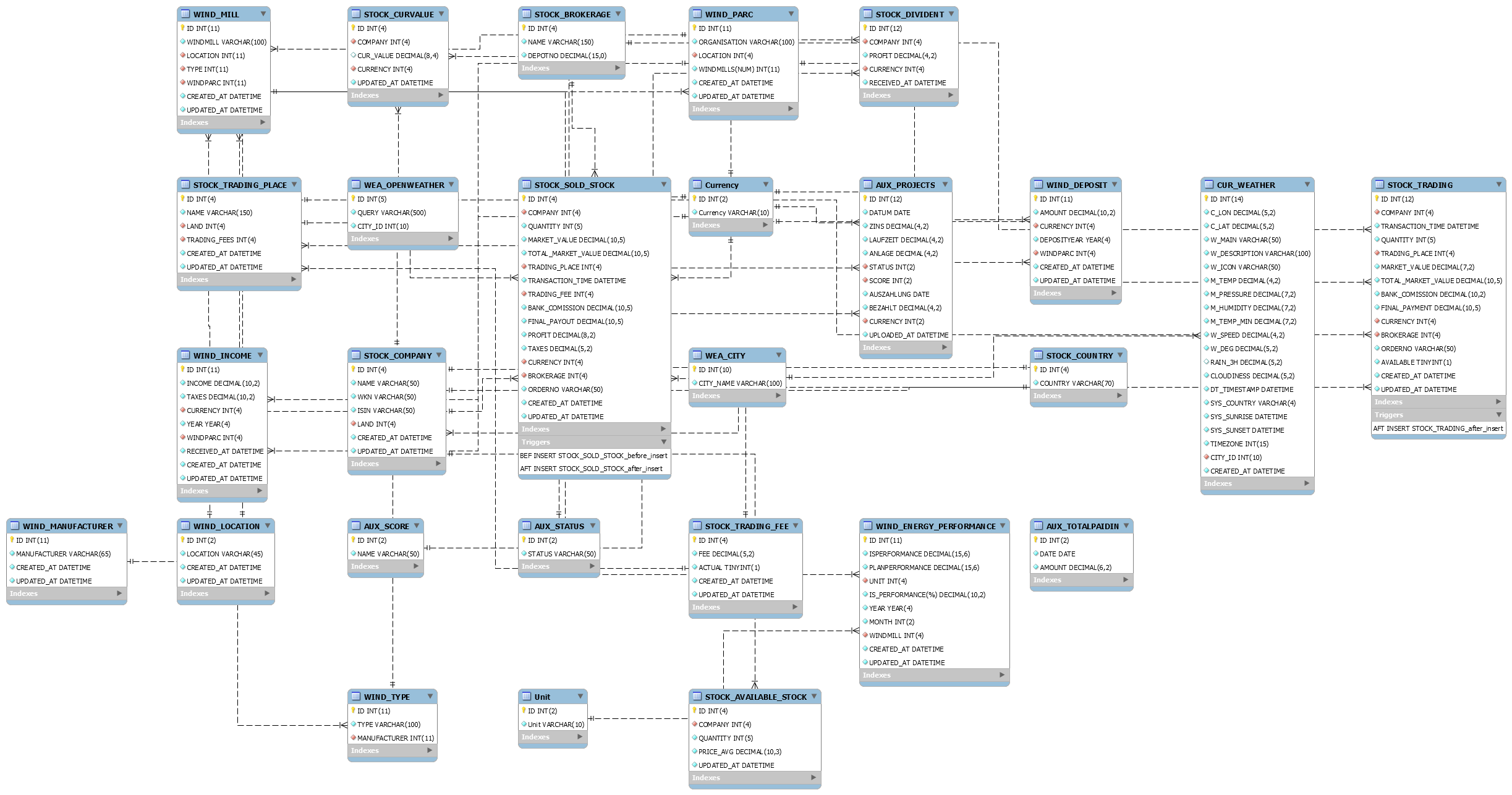
Gestern habe ich mehr oder weniger ein Schnappschuss vom Meteor Neowise gemacht. Dieser ist nur alle paar tausend Jahre zu sehen, daher wollte ich die Chance war nehmen und auch mich in die Liste derer eintragen, die von dem Meteor ein Foto gemacht haben. Mit der App Star Walk 2 konnte ich Neowise virtuell direkt aufspüren und wusste wo er ungefähr sein müsste. Auch wenn ich aus dem Büro fotografiert hatte, so kann ich mit dem Foto sehr gut leben :). Eigentlich wollte ich um 23:30 schon aufgeben, da ich den Meteor nicht am Himmel sah, konnte dann aber doch einen hauch dünnen Schweif am Himmel sehen. Ich hielt die Linse also drauf und tatsächlich, mit einer längeren Verschlusszeit ließ sich der Meteor ganz gut erkennen. Also Kamera wieder aufs Stativ. Am Fenster musste ich das Stativ provisorisch befestigen, um eine ruhige Position zu erhalten. Ich bin froh, dass diese Konstellation gehalten hat 🙂

Auf der Canon war mein Sigma 24mm Weitwinkelobjektiv. Auf Blende 1.4 hatte ich für knappe 30 Sekunden belichtet und dieses Bild ist dabei rum gekommen.

Ich bin sehr froh, dass ich das Bild geschossen habe. Es ist sehr interessant, Neowise auf ein eigenes Bild festgehalten zu haben. Bis zum Ende des Monats soll man ihn noch sehen können, ehe er im August in den Tiefen der Galaxie verschwindet. Wer weiß vielleicht wage ich noch ein weiteres Foto an einem besseren Spot.