Metabase Startup Script
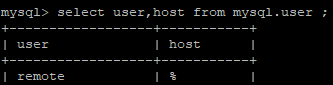
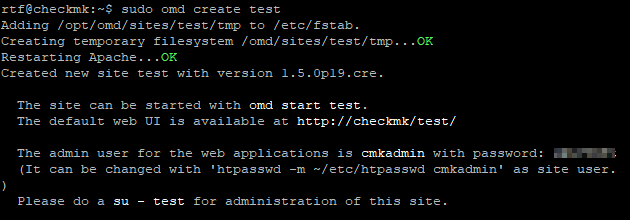
Damit Metabase automatisch starten, habe ich dieses Script geschrieben. Dafür überprüft es, ob Metabase, bzw. eine Java Instanz schon auf Port 3000 lauscht. Falls dies der Fall ist, gehe ich davon aus, dass Metabase schon läuft und schreibe es in die Variable alreadystarted. In die eventuallystarted schreibe ich, falls schon ein Java Dämon existiert. Dies könnte unter Umständen bedeuten, dass Metabase im Boot Mode ist und gerade gestartet wurde. In diesem Fall bricht das Script ab und man muss es manuell ausführen. Metabase ist definitiv nicht am Laufen, wenn beide Variablen nicht gesetzt sind. Dementsprechend sind die export Variablen für den Metabase Mysql Startup. Die STDOUT von Metabase wird in eine Log Datei weitergeleitet.
alreadystarted=`netstat -tapen | grep LISTEN | grep 3000 | awk '{print $9}'`
eventuallystarted=`ps -Al | grep java | awk '{print $4"/"$14}'`
echo "JAVA,METABASE:${eventuallystarted},${alreadystarted}"
if [ ! -z "$eventuallystarted" ]
then
if [ ! -z "$alreadystarted" ]
then
echo "[I] A Metabase Instance is already running!"
exit 0
fi
echo "[I] It may be that a Metabase Instance is already running. Please check and run manually!"
exit 1
fi
if [ -z "$alreadystarted" ]
then
export MB_DB_TYPE=mysql
export MB_DB_DBNAME=db
export MB_DB_PORT=3306
export MB_DB_USER=user
export MB_DB_PASS=password
export MB_DB_HOST=localhost
java -jar metabase.jar >> /var/log/Metabase/metabase`date +%V`.log &
else
echo "[I] A Metabase Instance is already running!"
exit 0
fi