Kali Linux 2021.4 wurde veröffentlich
Mit dem beinahen Ende von 2021 wurde Kali Linux 2021.4 als letztes Release für dieses Jahr veröffentlicht. Seit dem 09.12 ist die Version nun verfügbar und beinhaltet folgende Änderungen:
- Verbesserte Apple M1 Unterstützung
- Größere Samba Kompatibilität
- Package Manager Mirror konfigurieren
- Kaboxer Themen Unterstützung
- Neue Tools
- Desktop & Themen Erweiterungen
- Kali NetHunter Neuerungen
- Kali ARM Neuerungen
Verbesserte Apple M1 Unterstützung
Seit Kali 2021.1ist Kali auf dem Apple Silicon Macs lauffähig. Mit 2021.4 unterstützt es nun auch die VMware Fusion Public Tech Preview, dank des 5.14 Kernels, der die Module für die virtuelle GPU bereitstellt. Ebenfalls sind die open-vm-tools auf dem neusten Stand. Der Kali Installer erkennt automatisch die Installation unter VMware und installiert direkt das open-vm-tools-desktop Package. Zurzeit ist dies unter Beobachtung von VMware, es könnten also weiterhin Fehler auftreten.
Virtuelle Maschinen auf dem Apple Silicon sind, wie zuvor, auf ARM64 Installationen limitiert.
Größere Samba Kompatibilität
Mit Kali 2021.4 ist der Samba Client nun zu so gut wie mit allen Samba Servern kompatibel, egal welche Version vom Protokoll benutzt wird. Diese Änderung sollte es vereinfachen, Schwachstellen in Samba Servern zu finden, ohne dafür Kali zu konfigurieren. Mittels den kali-tweaks unter der Rubrik Hardening könnt ihr die Änderungen wieder zurück auf die Default Einstellungen setzen. In diesem Fall werden nur noch die neusten Versionen des Samba Protokolls unterstützt.
Package Manager Mirror konfigurieren
Normalerweise, wenn das Kali System mit apt geupdated wird, kommt eine Verbindung zu einem jeweiligen Community Mirror in der Nähe zustande. Es ist aber schon seit langem möglich, Packages von CloudFlare CDN herunterzuladen. Mit kali-tweaks kann nun zwischen den Community Mirrors und der Cloudflare CDN gewechselt werden.
Kaboxer Themen Unterstützung
Mit dem neusten Kaboxer Update, sieht jenes nicht mehr altbacken aus, da es Unterstützung für die Windows Themen und Icon Themen anbietet. Somit können Programme sich an die Desktopumgebung orientieren und verhindern eher unschöne fallback Themen. Als Beispiel Zenmap mit dem Standard Kali Dark Themen und dem alten Erscheinungsbild.
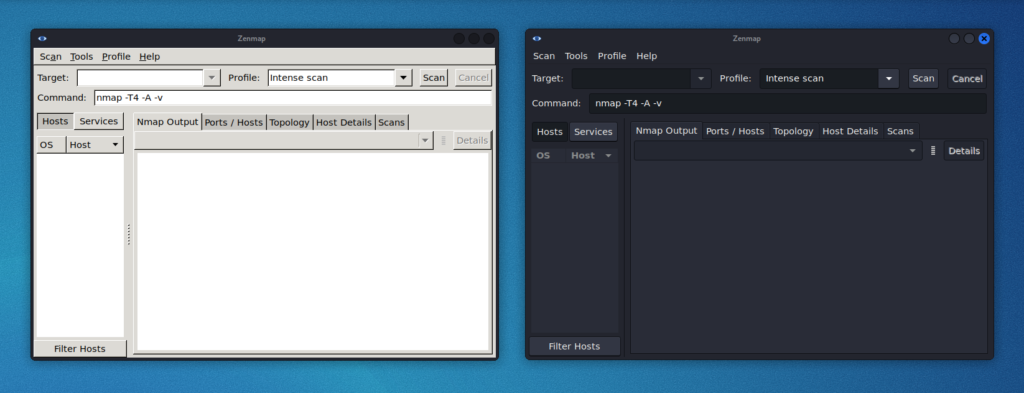
Neue Tools
Es wäre kein Kali Release, wenn es nicht auch neue Tools gibt:
- Dufflebag – Durchsuchen von Elastic Block Storage(EBS)
- Mayam – Open-source Intelligence (OSINT) Framework
- Name-That-Hash – Hashtyp ermitteln
- Proxmark3 – RFID hacking
- Reverse Proxy Grapher – Veranschaulichung des Reverse Proxy Flows
- S3Scanner – Scannt offenen S3 buckets
- Spraykatz – Benutzerdatenermittlung für Windows Maschinen und große AD Umgebungen
- truffleHog – Durchsuchen von git Repositories nach String und anderen Secrets
- Web of trust grapher (wotmate) – implementiert den veralteten PGP-Pfadfinder neu
Desktop & Themen Erweiterungen
Dieses Release bringt Neuerungen zu allen 3 Desktops, die sind Xfce, GNOME und KDE. Ein Update kommt für alle Desktops und das ist das neue Windows Button Design.

Xfce
Für Xfce gibt es etwas mehr horizontalen Platz, sodass 2 neue Widges: CPU Usage und VPN IP, Platz finden. VPN IP bleibe versteckt, solange es keine VPN Verbindung gibt. Zusätzlich hat sich der Taskmanager verändert und zeigt jetzt nur noch „icons only“ an. Die Panelhöhe wurde ebenfalls leicht erhöht.
Für das Terminal Dropdown Menu steht eine Powershell Verknüpfung zur Verfügung. Ihr könnt nun zwischen dem regulären Terminal, dem Root Terminal und Powershell wählen.
GNOME 41
GNOME hat indes 2 Versionssprünge gemacht. Seit dem letzten großen GNOME Update in Kali ist seither 1 Jahr vergangen. GNOME 40 und GNOME41 sind in der Zwischenzeit released worden. Alle Themen und Erweiterungen unterstützen die neue Shell.
KDE 5.23
Das KDE Team hat dieses Jahr ihr 25 Jähriges Bestehen gefeiert und veröffentlichten die 5.23 vom Plasma Desktop. Dieses Update ist nun in Kali verfügbar und bringt ein neues Design für das Breeze Themen mit.
Das Kali Themen update
All diese Themenänderungen werden nicht automatisch bei einem Kali Upgrade aktiviert. Dies ist aufgrund dessen, dass die Themen Settings unter dem Home Ordner des Users gespeichert sind, als dieser erzeugt wurde. Bei einem Kali upgrade wird das Betriebssystem upgedated aber nicht die persönlichen Dateien. Um die neuen Themen zu erhalten musst du entweder
- Kali neu installieren
- einen neuen User erzeugen und mit dem weiterarbeiten
- das Desktopumgebungsprofil für den Benutzer löschen und ein reboot veranlassen. Hier ein Beispiel anhand von Xfce
kali@kali:~$ mv ~/.config/xfce4{,-$(date +%Y.%m.%d-%H.%M.%S)}
kali@kali:~$
kali@kali:~$ cp -rbi /etc/skel/. ~/
kali@kali:~$
kali@kali:~$ xfce4-session-logout --reboot --fast
Kali NetHunter Neuerungen
Für die Kali NetHunter App steht mit der 2021.4 ein Social-Engineer Toolkit zur Verfügung. Es können nun eigene Facebook, Messenger oder Twitter Emails versendet werden.
Kali ARM Neuerungen
- Alle Images benutzen nun ext4 für deren root Dateisystem.
- Support für den Raspberry Pi Zero 2 W. Wie bei dem Raspberry Pi 400 gibt es keine Nexmon Unterstützung
- Raspberry Pi Images unterstützen nun out of the box das Booten vom USB, da das root device nicht länger hardgecoded ist.
Quelle: https://www.kali.org/blog/kali-linux-2021-4-release/
Das Update
Um eine bestehende Installation auf 2021.4 upzudaten, führt folgende Befehle aus
sudo apt update sudo apt -y full-upgrade sudo reboot
mit dem nächsten Befehl könnt ihr überprüfen, ob die Version 2021.4 installiert ist
cat /etc/os-release PRETTY_NAME="Kali GNU/Linux Rolling" NAME="Kali GNU/Linux" ID=kali VERSION="2021.4" VERSION_ID="2021.4" VERSION_CODENAME="kali-rolling" ID_LIKE=debian ANSI_COLOR="1;31" HOME_URL="https://www.kali.org/" SUPPORT_URL="https://forums.kali.org/" BUG_REPORT_URL="https://bugs.kali.org/"