Ich habe schon immer mit einem Sprachassistenten geliebäugelt. Der teils vorhandene onlinezwang sowie die Erforderlichkeit den Sprachassistenten mit google, amazon, etc. zu verbinden, haben mich davor abgehalten einen zu ordern. Jetzt habe ich mir einen eigenen offline Sprachassistent mit Python erstellt. Als Spracherkennungsbibliothek verwende ich vosk. Vosk unterstützt mehr als 20 Sprachen, darunter auch deutsch und englisch. Die Spracherkennung funktioniert offline und sogar auf lightweight devices wie den Raspberry Pi.
Zur Einrichtung benötigen wir ein auf deutsch trainiertes Model. Von Vosk werden welche bereitgestellt, ihr könnt aber auch eigene Modelle erstellen.
Installation und Einrichtung
Die Installation von Vosk erledigen wir mit dem pip Manager. Für die Integration unseres Mikrophones ist sounddevice erforderlich. Zum Testen unserer Geräte installieren wir die alsa-utils, die eine Palette an Programme bereitstellt, unteranderem arecord und aplay.
# Abhängigkeiten installieren sudo apt install python3-pyaudio alsa-utils libgfortran3 pip3 install vosk pip3 install sounddevice
Wir laden uns zuerst das github von vosk herunter. Dort sind ebenfalls einige Beispiel Skripte enthalten. Geht in das Beispiel Verzeichnis und ladet ein Model eurer Wahl, um so vosk die Fähigkeit zu geben, unser Gesprochenes in Text umzuwandeln. Wichtig ist, dass das geladene und entpackte Model-Verzeichnis nach model umbenannt wird. Alle verfügbaren Models findet ihr hier: https://alphacephei.com/vosk/models
git clone https://github.com/alphacep/vosk-api cd vosk-api/python/example wget https://alphacephei.com/vosk/models/vosk-model-small-de-0.15.zip unzip vosk-model-de-0.21.zip mv vosk-model-de-0.21/ model
Falls ihr noch kein Benutzer der Gruppe audio seid, fügt euch bitte hinzu. Ansonsten fehlen euch unter umständen die Berechtigungen, Aufnahme- und Ausgabegeräte zu benutzen.
development:~# grep audio /etc/group audio:x:29:<user> sudo reboot
Sounddevice/Mikrofon testen
Als Sounddevice kommt ein USB Mikrofon zum Einsatz. Bei Amazon habe ich mir das Tyasoleil USB Mikrofon gekauft, und muss sagen, dass ich mehr als beeindruckt bin. Es kann mich im kompletten Raum aufnehmen. Ich habe es hier verlinkt: Mikrofone*. Mit arecord können wir die verfügbaren Aufnahmegeräte auflisten.
arecord -l **** List of CAPTURE Hardware Devices **** card 0: I82801AAICH [Intel 82801AA-ICH], device 0: Intel ICH [Intel 82801AA-ICH] Subdevices: 1/1 Subdevice #0: subdevice #0 card 0: I82801AAICH [Intel 82801AA-ICH], device 1: Intel ICH - MIC ADC [Intel 82801AA-ICH - MIC ADC] Subdevices: 1/1 Subdevice #0: subdevice #0
Ebenfalls bietet es uns die Möglichkeit eine Aufnahme zu starten und später als .wav Datei zu speichern.
arecord -f S16_LE -d 10 -r 16000 ./test-mic.wav Recording WAVE './test-mic.wav' : Signed 16 bit Little Endian, Rate 16000 Hz, Mono
Mit aplay können wir unsere gerade erstellte .wav Datei anhören und so die Tests des Mikrofons abschließen.
aplay test-mic.wav Playing WAVE 'test-mic.wav' : Signed 16 bit Little Endian, Rate 16000 Hz, Mono
Python3 Code
Zuerst laden wir die benötigten Python Bibliotheken. und erstellen eine Queue. Queue ist eine Art lineare Datenstruktur und arbeitet nach dem FIFO Prinzip. FIFO stammt aus dem englischen und bedeutet First-In-First-Out. Kurz gesagt, was zuerst reinkommt, geht auch als erstes wieder raus. Wir haben einen zusätzlichen Thread, der die Aktivphase managed und für 10 Sekunden offen hält. Dazu aber später mehr.
import argparse import os import queue import sys import json import sounddevice as sd import vosk import threading import time import gpiozero q = queue.Queue()
Activities Klasse
In der Activities Klasse sind alle Aktivitäten aufgelistet, die wir benutzen können. Zurzeit beschränken wir uns auf Licht an/aus und Tor an/aus. In beiden Fällen triggern wir eine LED, die mit unterschiedlichen GPIO gesteuert wird.
Speech Klasse
Die Speech Klasse ist die Hauptklasse. Hier wird der Startcode definiert, auf dem unsere Sprachsteuerung reagiert und nach dem wir unsere Kommandos sagen können. Der Startcode ist ähnlich wie „alexa“ bei Amazon. Wurde der Startcode herausgehört, haben wir ein 10 Sekunden Fenster für die Kommandos, ehe wir unseren Startcode erneut sagen müssen. Während unser Sprachfenster offen ist, leuchtet zusätzlich noch eine grüne LED. Die 10 Sekunden Zählschleife, unsere Aktivphase, ist in einem Thread gepackt und läuft im Hintergrund. Ebenso wie das an und ausschalten der grünen LED. Das hat den Vorteil, dass unser Programm weiterhin auf das Gesprochene reagieren kann, während es die Zeit herunterzählt. Solange unser Thread läuft, können wir die Activities Methoden mit unserer Sprache steuern.
class Activities:
# Definiere die Aktivitäten, die mit deiner Sprache gesteuert werden können.
LICHT_LED = LED_TOR = None
def licht(GPIO):
# Schalte das Licht an und aus
print(f" Schalte das Licht an/aus mit {GPIO}")
if Activities.LICHT_LED is None:
Activities.LICHT_LED = gpiozero.LED(GPIO)
try:
Activities.LICHT_LED.toggle()
# if any error occurs call exception
except gpiozero.GPIOZeroError as err:
print("Error occured: {0}".format(err))
def tor(GPIO):
# zur Demonstrationszwecken wird hier nun eine Ausgabe definiert.
print(f" Schalte das Tor an mit {GPIO}")
class speech:
STARTCODE = 'computer'
def __init__(self,startcode):
self.STARTCODE = startcode
# Unsere Thread Funktion
def thread_timer(self):
# Aktiviere GPIO 17, um die grüne LED zum Leuchten zu bringen.
led = gpiozero.LED(17)
self.power_gpio(17,led)
# warte 10 Sekunden
time.sleep(10)
# Schalte die grüne LED wieder aus.
self.close_gpio(17,led)
# Definieren der Aktivierungsphase. Solange der thread gestartet ist, können Kommandos zum triggern der Methoden aus der Activities Klasse gesagt werden.
#
def active(self,rec):
print("active")
# Thread definieren
t = threading.Thread(target=self.thread_timer)
# Thread starten
t.start()
i=0
# solange Thread aktiv
while t.is_alive():
print('call a command')
# hole die Daten aus der Queue, bzw. aus dem Stream
data = q.get()
if rec.AcceptWaveform(data):
print("second record")
#
res = json.loads(rec.Result())
if 'LICHT'.upper() in res['text'].upper():
Activities.licht(18)
elif 'Tor'.upper() in res['text'].upper():
Activities.tor(18)
print(res['text'])
def power_gpio(self,GPIO,led):
print(f"Power {GPIO}")
try:
# switch LED on
if not led.is_lit:
led.on()
# if any error occurs call exception
except gpiozero.GPIOZeroError as err:
print("Error occured: {0}".format(err))
def close_gpio(self,GPIO,led):
print(f"Close {GPIO}")
try:
# switch LED off
if led.is_lit:
led.off()
# if any error occurs call exception
except gpiozero.GPIOZeroError as err:
print("Error occured: {0}".format(err))
Main
In der Main parsen wir die Argumente, die wir dem Programm übergeben können. Falls keine angegeben worden sind, übernimmt das Script definierte Standardwerte. Wir überprüfen, ob der Ordner model existiert und erstellen ein Objekt der Klasse speech mit unserem definierten Aktivierungswort. Unsere Sprache muss natürlich noch aufgezeichnet werden. Dies machen wir mit der Methode RawInputStream der sounddevice Klasse. Wichtig hier ist vor allem der callback Parameter vom Typ „callable“. Diesem geben wir unsere gleichnamige Funktion über, die folgenden Aufbau benötigt:
callback(indata: buffer, frames: int,
time: CData, status: CallbackFlags) -> None
In dieser Funktion geben wir unserem Sprach-Stream, den wir zuvor mit RawInputStream eingefangen haben, als Bytes in die am Anfang definierte Queue. In unserer while Schleife entnehmen wir unserer Queue die Daten und übergeben diese der Methode AcceptWaveForm. Die gerade genannte Methode versucht die gesprochenen Sätze zu erkennen. Erst wenn es das Ende vermutet, gibt AcceptWaveForm True zurück. In rec.Result() befindet sich das Ergebnis des gesprochenen Textes. Wird erhalten ein String, den wir mit json.loads als JSON parsen und weiterverarbeiten können. Wird da Aktivierungswort herausgehört, geht es mit dem gleichen Vorgehen im Aktivierungsfenster weiter.
def callback(indata, frames, time, status):
"""This is called (from a separate thread) for each audio block."""
if status:
print(status, file=sys.stderr)
pass
q.put(bytes(indata))
if __name__ == '__main__':
parser = argparse.ArgumentParser(add_help=True)
parser.add_argument(
'-m','--model', type=str, nargs='?',default='model', help='Pfad zum Model'
)
parser.add_argument(
'-d','--device', type=str,nargs='?',default='1,0',help='Eingabegerät(Mikrofon als String)'
)
parser.add_argument(
'-r','--samplerate',type=int,nargs='?', default=44100,help='Sample Rate'
)
args = parser.parse_args('')
if not os.path.exists(args.model):
print("Please download a model from https://alphacephei.com/vosk/models and unpack to 'model'")
#exit(1)
model = vosk.Model(args.model)
# Speech Objekt erstellen und Übergabe des Aktivierungsworts
speech = speech('computer')
#
with sd.RawInputStream(samplerate=args.samplerate, blocksize=8000, device=None,dtype='int16',
channels=1, callback=callback):
print('*' * 80)
# Aktivierung der vosk Spracherkennung mit Übergabe des geladenen Models. Übersetze das Gesprochene in Text.
rec = vosk.KaldiRecognizer(model, args.samplerate)
while True:
# Daten aus der Queue ziehen
data = q.get()
print("start to speak")
if rec.AcceptWaveform(data):
# erhalte das erkannte gesprochene als String zurück
x = rec.Result()
print(x)
print(rec.Result())
# wandelt den String in Json um
res = json.loads(x)
print(res)
# wenn der Aktivierungscode herausgehört wurde, wird die active Methode von Speech gestartet
if speech.STARTCODE == res['text']:
speech.active(rec)
else:
pass
Aufbau der Schaltung
Vom Prinzip her sind es zwei die gleichen Schaltungen. Nur der benutzte GPIO Pin ist ein anderer. Beide LEDs sind mit einem 330 Ohm Wiederstand geschaltet. Der Rest kann in der Schaltung begutachtet werden.
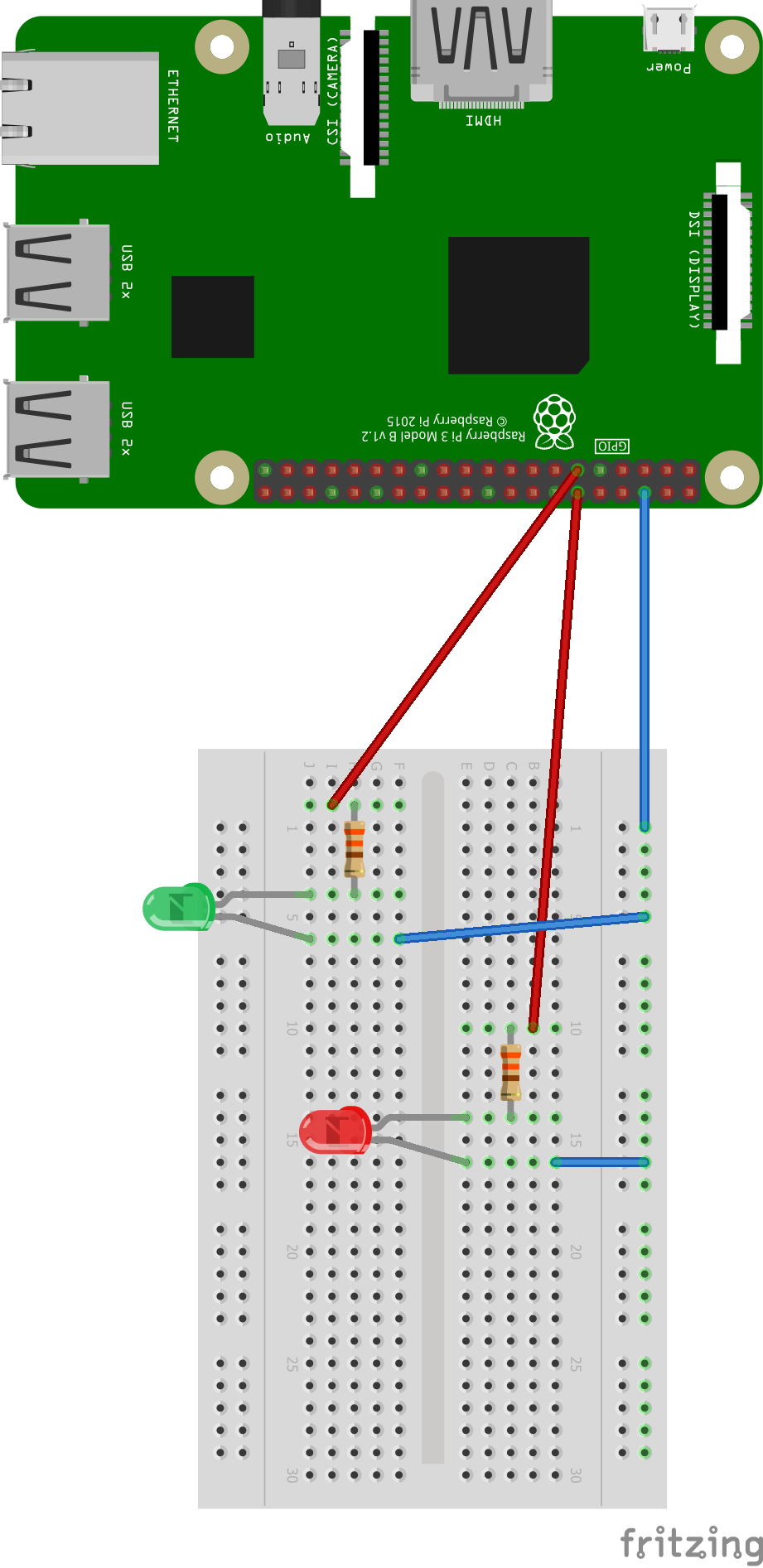
Den kompletten Code findet ihr bei github.
Update: Ich habe den Sprachassistenten nun mit einem LED-Streifen verbunden. Den Beitrag findet ihr hier: LED-Streifen mit offline Sprachassistenten steuern
8 Gedanken zu „Offline Sprachassistent mit Python“
Echt guter Beitrag! Ich konnte meine Sprachsteuerung auf deinen Code aufbauen.
Moin,
das freut mich, dass du deine Sprachsteuerung damit aufbauen konntest.
Viele Grüße
stevie
Hi,
ich würde gerne ganze mp3-Files (mehrere Stunden lang) mit speech2txt „an einem Stück“ verarbeiten.
Und zwar privacy-konform und offline (also ohne google-api etc.).
Hast Du dafür eventuell auch einen Tipp?
Danke!
Hallo,
leider kann ich hier nicht auf Anhieb weiterhelfen. Was wollen sie den genau mit den mp3 machen? sollen die durch eine Sprachdurchsage abgespielt werden?
Viele Grüße
stevie
Hallo,
ich bin schon seit längerem auf der Suche nach genau so einer Anwendung.
Bevor ich das ganze allerdings direkt nachbaue, wie schnell aund genau reagiert dieser Sprachassistent denn bei deiner verwendeten Hardware? Bei mir würde er vermutlich auf einem Rpi 4 mit 8GB RAM laufen.
Vielen Dank schonmal, das ist ein super Projekt.
Hallo Tobias,
in meinem zweiten Beitrag zum Thema habe ich ein Video dazu gepostet. Mit der Perfomance und Genauigkeit bin ich zufrieden. Wenn viele Nebengeräusche da sind wirds aber auch schon schwieriger mit der Genauigkeit. Mit dem verbauten Mikro konnte ich aber quer durch den Raum das Licht an und aus schalten.
Hier findest du den zweiten Beitrag: https://steviesblog.de/blog/2022/01/20/led-streifen-mit-offline-sprachassistenten-steuern/
Viele Grüße
stevie
Hallo,
find ich super – ich stiess mit google drauf, weil ich für gpt4all Sprachein-, ausgabe offline basteln wollte. Ich habe Dein Programm gekürzt und für gpt4all umgefummelt und es funktioniert:
from gpt4all import GPT4All
import pyttsx3
import vosk
import sounddevice as sd
import json
import queue
def callback(indata, frames, time, status):
„““This is called (from a separate thread) for each audio block.“““
if status:
print(status, file=sys.stderr)
pass
q.put(bytes(indata))
modelgpt4all = GPT4All(„em_german_mistral_v01.Q4_0.gguf“)
q = queue.Queue()
engine = pyttsx3.init()
engine.say(„Starte Spracherkennung mit Aktivierungswort computer“)
engine.runAndWait()
modelvosk = vosk.Model(„model/vosk-model-small-de-0.15“)
with sd.RawInputStream(samplerate=44100, blocksize=8000, device=None,dtype=’int16′, channels=1, callback=callback):
rec = vosk.KaldiRecognizer(modelvosk, 44100)
while True:
data = q.get()
print(„Bitte sprechen“)
if rec.AcceptWaveform(data):
x = rec.Result()
res = json.loads(x)
print(res[‚text‘])
if „computer“ == res[‚text‘][0:8]:
print(„Aktivierungskommando erkannt! *******************************************“)
with modelgpt4all.chat_session():
answer=modelgpt4all.generate(res[‚text‘][8:], max_tokens=1024)
print(answer)
engine.say(answer)
engine.runAndWait()
else:
pass
Moin Klaus,
schön das der Beitrag geholfen hat 🙂
Viele Grüße
stevie