check_mk Update durchführen
Das Update von check_mk verhält sich ein wenig anders als man es gewohnt ist. Es muss zuerst dass jeweilige Paket runtergeladen und installiert werden. Achtet dabei auf die Version, die ihr haben wollt und die Edition, die ihr benötigt. Nehmt aus der unteren Tabelle das Editionskürzel. CRE ist dabei die kostenlose Variante. Auf der Seite werden die unterstützten Distributionen aufgelistet. Ladet eure richtige Version herunter.
https://checkmk.de/download_version.php?&version=1.6.0&edition=cee
Die Dateiendung .cee steht für Checkmk Enterprise Edition. Neben dieser gibt es noch
| .cre | Checkmk Raw Edition |
| .demo | Demo Version der Checkmk Enterprise Edition |
| .cme | Checkmk Managed Services Edition |
wgett https://checkmk.de/support/1.6.0/check-mk-enterprise-1.6.0_0.xenial_amd64.deb
Überprüfen wir die aktuelle check_mk Version auf dem Server, sehen wir noch die anderen Versionen die zur Verfügung stehen. Die Besonderheit an check_mk ist, dass wir alle Instanzen(Sites) mit einer unterschiedlichen Version laufen lassen könnten.
omd versions Ausgabe: 1.2.8p18.cee 1.4.0b4.cee 1.4.0p5.cee (default)
Listen wir die Sites auf, so sehen wir, dass wir 2 zur Verfügung haben.
omd sites Ausgabe: SITE VERSION COMMENTS Testsite2 1.4.0p5.cee default version checkmk 1.4.0p5.cee default version
Da jede Instanz einen gleichnamigen User in Linux erzeugt, habe ich mir die passwd ebenfalls angeschaut, ob der relevante User immer noch vorhanden ist. Dieser Schritt ist allerdings optional und wird nicht benötigt.
grep omd /etc/passwd checkmk:x:999:1001:OMD site checkmk:/omd/sites/checkmk:/bin/bash Testsite2:x:997:1006:OMD site Testsite2:/omd/sites/Testsite2:/bin/bash
Zur Installation benutzen wir dpkg mit dem Parameter -i.
sudo dpkg -i check-mk-raw-1.6.0_0.bionic_amd64.deb
Überprüfen wir nun ein weiteres mal die check_mk Versionen, sehen wir die gerade installierte.
sudo omd versions 1.2.8p18.cee 1.4.0b4.cee 1.4.0p5.cee 1.6.0.cee (default)
Die Instanzen werden nicht automatisch auf die neuste Version gebracht. Damit dies geschieht, müssen wir uns vorerst als den Site User anmelden.
sudo su <Instanzuser>
Geben wir
omd version
ein, so sehen wir, dass sich für diese Instanz die Version nicht geändert hat, was wir nun nachholen.
sudo su checkmk OMD[checkmk]:~$ omd version OMD - Open Monitoring Distribution Version 1.4.0p5.cee
Achtet bitte darauf, dass ihr immer noch als der Instanz User angemeldet seid!
Zuerst müssen wir die Instanz stoppen.
omd stop Removing Crontab...OK Stopping apache...killing 1393....OK Stopping nagios....OK Stopping npcd...OK Stopping rrdcached...waiting for termination...OK Stopping mkeventd...killing 1286...OK Stopping 1 remaining site processes...OK
Das Update
Nach dem die Instanz gestoppt ist, können wir mit dem Update beginnen.
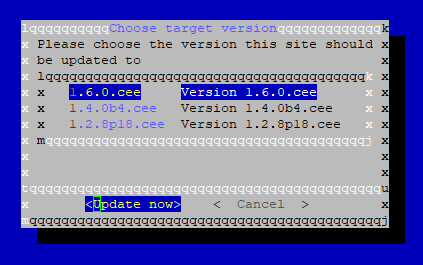
omd update
Es sollte ein Abfragefenster mit einer Warnung auftauchen, in der ihr explizit das Update genehmigen müsst.
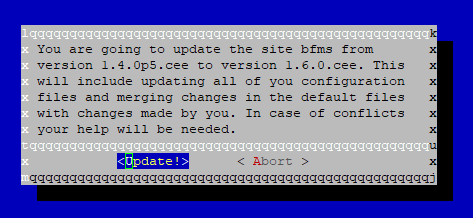
Nachdem bestätigt wurde, wird das Update für die Instanz installiert.
So sah bei mir die Ausgabe aus:
* Updated .profile * Installed link var/dokuwiki/lib/plugins/cli.php * Installed dir local/share/check_mk/web/htdocs/themes * Installed dir etc/stunnel * Merged etc/mk-livestatus/xinetd.conf * Updated etc/nagvis/nagvis.ini.php * Updated etc/dokuwiki/dokuwiki.php * Updated etc/dokuwiki/mime.conf * Updated etc/dokuwiki/local.php * Installed link etc/rc.d/85-stunnel * Installed file etc/logrotate.d/stunnel * Updated etc/check_mk/apache.conf * Updated etc/init-hooks.d/README * Updated etc/apache/apache.conf * Installed file etc/apache/conf.d/security.conf * Updated etc/apache/conf.d/omd.conf * Installed file etc/apache/conf.d/01_wsgi.conf * Installed file etc/init.d/stunnel * Installed file etc/stunnel/server.conf * Vanished etc/icinga/ssi/extinfo-header.ssi * Vanished etc/icinga/ssi/status-header.ssi * Vanished etc/icinga/ssi/README * Vanished etc/icinga/icinga.d/omd.cfg * Vanished etc/icinga/icinga.d/timing.cfg * Vanished etc/icinga/icinga.d/mk-livestatus.cfg * Vanished etc/icinga/icinga.d/flapping.cfg * Vanished etc/icinga/icinga.d/obsess.cfg * Vanished etc/icinga/icinga.d/misc.cfg * Vanished etc/icinga/icinga.d/retention.cfg * Vanished etc/icinga/icinga.d/logging.cfg * Vanished etc/icinga/icinga.d/freshness.cfg * Vanished etc/icinga/icinga.d/dependency.cfg * Vanished etc/icinga/icinga.d/eventhandler.cfg * Vanished etc/icinga/icinga.d/tuning.cfg * Vanished etc/icinga/idomod.cfg-sample * Vanished etc/icinga/apache.conf * Vanished etc/icinga/cgiauth.cfg * Vanished etc/icinga/resource.cfg * Vanished etc/icinga/icinga.cfg * Vanished etc/icinga/config.inc.php * Vanished etc/icinga/cgi.cfg * Vanished etc/icinga/icinga.d * Vanished etc/icinga/conf.d * Vanished etc/icinga/ssi * Vanished etc/init.d/icinga * Vanished etc/apache/conf.d/01_python.conf * Vanished etc/rc.d/80-icinga * Vanished etc/icinga * Vanished local/share/icinga/htdocs * Vanished local/share/icinga * Vanished local/lib/icinga * Vanished var/icinga Executing update-pre-hooks script "cmk.update-pre-hooks"...OK Output: Initializing application... Loading GUI plugins... Updating Checkmk configuration... + Rewriting WATO tags... + Rewriting WATO hosts and folders... + Rewriting WATO rulesets... + Rewriting autochecks... Done Finished update.
Das Update wäre nun vollzogen und wir können die Instanz wieder starten:
omd start Creating temporary filesystem /omd/sites/test/tmp...OK Starting mkeventd...OK Starting rrdcached...OK Starting npcd...OK Starting nagios...OK Starting apache...OK Initializing Crontab...OK
Nach Abschluss sollte der Status und die Version ein weiteres Mal überprüft werden.
OMD[test]:~$ omd status mkeventd: running rrdcached: running npcd: running nagios: running apache: running crontab: running ----------------------- Overall state: running OMD[test]:~$ omd version OMD - Open Monitoring Distribution Version 1.6.0.cre
Ihr solltet unbedingt die Release Notes auf etwaige Inkompatibilitäten überprüfen, sowie Änderungen, die anfallen.